

开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。
无独有偶,谷歌近期也发布了一篇被誉为“Attention is all you need”V2(Nested Learning: The Illusion of Deep Learning Architectures)的重磅论文,核心同样指向记忆瓶颈。
就连最近这只彻底破圈的AI大龙虾——OpenClaw(原名Clawdbot),其亮点之一依旧是记忆。
也就是说,记忆≈今年全球AI圈集体押注的技术风口≈皇冠明珠。
几乎所有你能想到的大模型团队,都在加班加点往自家模型里塞记忆功能……
但这一次,让我们把视线从这些科技巨头身上稍稍挪开,就会发现有一支后起之秀同样不容小觑。
他们就是陈天桥和邓亚峰带队的EverMind。
为什么这样说呢?
且看产品,最新发布世界级长期记忆系统——EverMemOS,发布即SOTA。
一举打破多项记忆基准测试的同时,还能远超此前所有的基线方法。
其次,它是真正能用的。
不是只会跑测试的“花架子”,实际部署后效果照样能打。而且团队有底气有信心,技术代码全部开源。
为了方便开发者使用,他们刚刚还专门上线了云服务——现在只需一个最简单的API,就能直接将最前沿的大模型记忆能力装进自己的应用。
并且要知道,从EverMemOS正式立项到开源,团队只用了短短四个月时间,这是什么实力不必多说。
不止如此,EverMind更是联手OpenAI等十多个技术社区豪掷英雄帖,发起首届记忆起源大赛(Memory Genesis Competition 2026),号召全球顶尖人才前来共同书写记忆元年。
Anyway,下面我们娓娓道来。
大模型的记忆断裂GAP
在展开聊聊EverMemOS为啥强之前,我们不妨先来思考一个问题:当你使用大模型时,是不是总觉得有什么地方不得劲?
前一秒还聊得好好的,下一秒就忘得一干二净,要么就是拆东墙补西墙,这个记住了,另一个又忘了。
归根结底,不是模型能力不够强,而是记忆功能不够用。
这就要回到大模型的底层架构上讲,众所周知,当前大模型普遍用的是Transformer架构,其记忆核心在于自注意力机制,也就是上下文窗口的信息缓存。
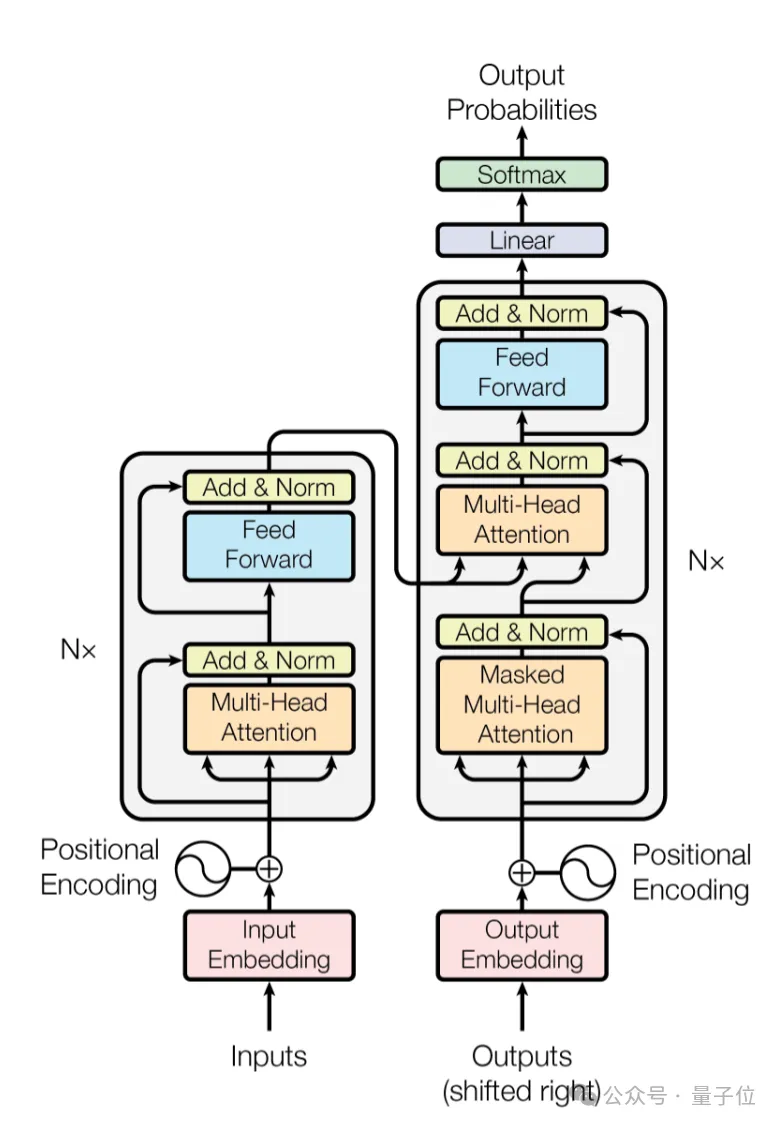
它会通过计算当前窗口的token间关系,理解上下文含义,但实际运行中由于受限于物理内存资源,窗口长度是有限的,一旦文本长度超过窗口限制,信息就会被截断遗忘。
另外,随着对话变长,KV Cache占用的显存也会逐渐膨胀。影响推理效率的同时,为了节省资源,现有的技术往往会选择压缩旧记忆,从而导致记忆细节变得模糊。
这显然影响了用户的实际体验,举个例子be like:
当你需要AI协助写一篇论文时, 从确定选题→检索相关文献→拟结构→写初稿→修改优化到最后定稿,这当中势必需要多轮交互,但AI压根记不住你之前写的内容,最后输出的结果也只能是驴头不对马嘴。
那怎么办呢?学术界为此提出了三种技术方案:
• 基于外部存储的记忆(External Storage based Memory)
这就类似于为大模型配备了一个外部数据库,里面系统存储着用户相关的历史记录。当用户提问时,系统就会先去数据库里搜索相关文档,再将其和问题一起喂给AI。
但这并非真正的记忆,而是在考场上临时翻阅教材。
• 基于模型参数的记忆(Model Parameter based Memory)
该方案本质是将记忆通过训练内化成模型的一部分,通过微调SFT或持续预训练,让模型在看到某个问题时,就能迅速通过参数内部权重指向正确答案。
DeepSeek的最新成果便是用的这个思路,但再训练的成本极高且容易遗忘,不适合个性化和短期记忆。
• 基于隐状态的记忆(Latent State based Memory)
通过保存模型的中间推理状态(如KV Cache),达成类人的短期记忆或工作记忆。
它非常适用于理解复杂的对话语境,但换言之,它是一次性的,只能短暂存在,无法长久记忆。
其中业界用的比较多的方法,还是RAG(检索增强生成),也就是基于外部存储的记忆。
但RAG同样缺点明显。首先,其工作方式是将长文本切成一个个片段,会破坏信息的连贯性,让模型难以理解复杂的因果关系。
其次RAG依赖向量相似度检索,擅长找语义相近的内容,但在时序匹配上不足;另外RAG知识是相对静态的,如果要更新信息,则需要高昂的成本支持。

基于此,EverMemOS应运而生。
学习大脑记忆机制,成了
启发于脑科学技术的研究成果,盛大一直以来非常重视长期记忆领域的研究。早在2024年10月,盛大团队就对外发布了长期记忆领域的纲领性文章《Long Term Memory-The Foundation of AI Self-Evolution》。
基于盛大多个团队在该领域的持续积累,EverMind在2025年8月正式启动EverMemOS项目,并于11月对外正式发布开源版本。
EverMemOS是EverMind打造的首款AI记忆基础设施,对比同赛道团队,似乎姗姗来迟。
Mem0、Zep等产品最早都能追溯到2024年,现在商业化最成功的开发者框架Letta(原MemGPT)也是2023年就开始起步。
EverMemOS却交出了亮眼的答卷:最晚入场,但效果弯道超车。
从技术角度看,它同时继承了基于外部存储和基于隐状态两种路径。不过业内并非没有尝试过此类方案,但EverMind显然在记忆提取的精准度和逻辑一致性上实现了更优的平衡。
原因在于EverMind抓住了精髓,用邓亚峰的话说,就是:
通过EverMemOS,我们赋予智能体一个活的、不断演化的历史。
这里的关键词其实是“活的”。那么如何能保存最鲜活的记忆呢?人类大脑。
这就引出了EverMind的独特思路——生物启发。
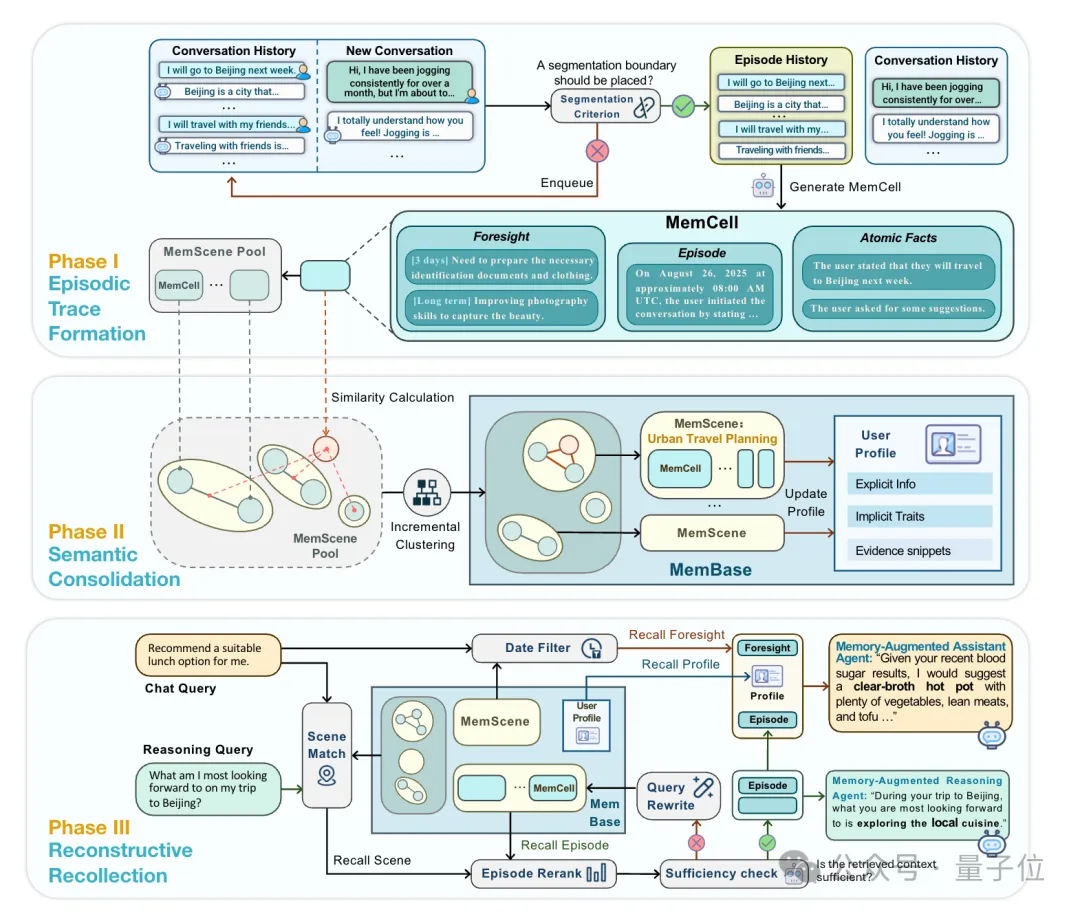
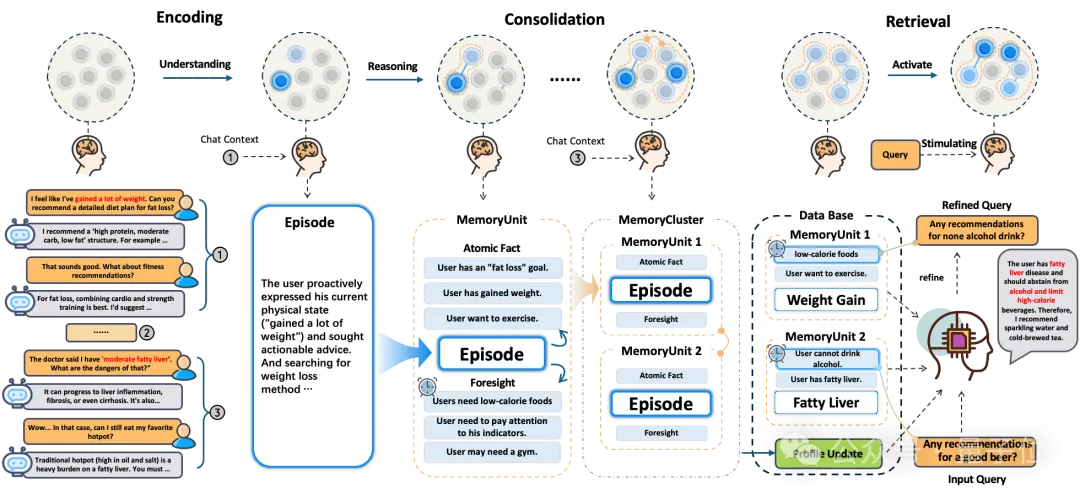
具体来讲,EverMemOS通过模拟人类记忆的形成并转化为计算框架,利用三阶段层层递进以实现大模型长期记忆的存储和提取:
Step 1:情景轨迹构建。
对应人脑的海马体和内嗅皮层,可以将连续的对话内容拆分成一个个独立的记忆单元(MemCell),每个单元里不仅记录有完整的聊天内容,还包括一些关键事实、时效信息等。
Step 2:语义整合。
类比新皮层(前额叶皮层+颞叶皮层),系统会将内容相关的记忆单元归类在一起,形成主题化的记忆场景(MemScene),同时还会更新用户画像,区分用户的长期稳定偏好和短期临时状态。
Step 3:重构式回忆。
这一步对应的是前额叶皮层和海马体的协同机制,当用户提问时,系统就会在记忆场景的引导下进行智能检索,只挑选出必要且足够的记忆内容,用于后续的推理任务。
由此,AI学会像人类一样记忆——这不仅是知识的数据库存储,更是认知系统的深度整合。如此一来,即便是在多个Agent之间,也能实现信息的高效传递。
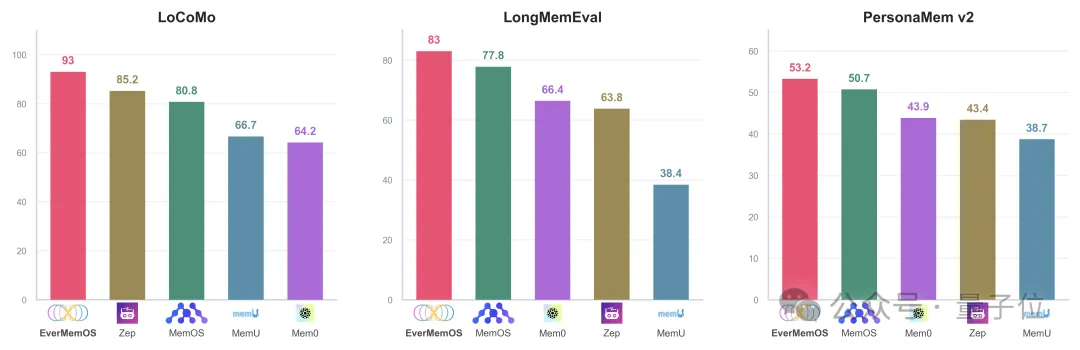
至于效果如何,咱们还是眼见为实,看看基准测试结果。
团队选取了4个主流记忆基准测试,以及多种大模型记忆增强方法。所有方法都基于同一基础大模型(GPT-4o-mini或GPT-4.1-mini)进行测试。
结果也很明显,EverMemOS大获全胜,全面超越现有记忆系统和全上下文模型。
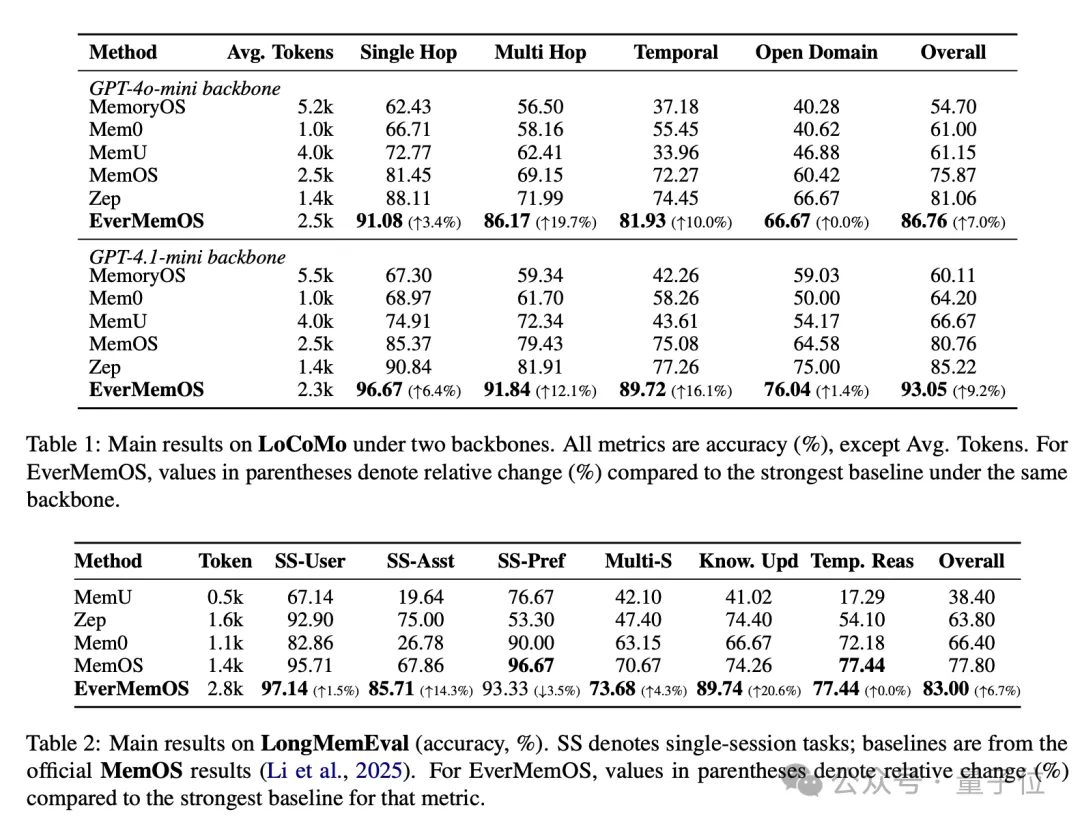
其中在LoCoMo上,准确率直接一跃来到93.05%,尤其是在多跳推理和时序任务上表现突出,分别提升19.7%和16.1%,同时token使用量和计算成本得到大幅度降低。
在多会话对话评估LongMemEval里,EverMemOS同样以83%的准确率位居榜首,说明在面对跨度极大、信息量极高的场景中,EverMemOS依旧能够精准检索和关联到过去的信息,并且通过持续交流还会不断进化完善自己。
HaluMem由MemTensor和中国电信研究院联合发布,是业界首个面向AI记忆系统的操作级幻觉评估基准。而EverMemOS在保证记忆完整性的同时,也显著改善了幻觉现象。
在PersonaMem v2里,EverMemOS在九个复杂场景中依旧全场最佳,保证了深度个性化和行为一致性。
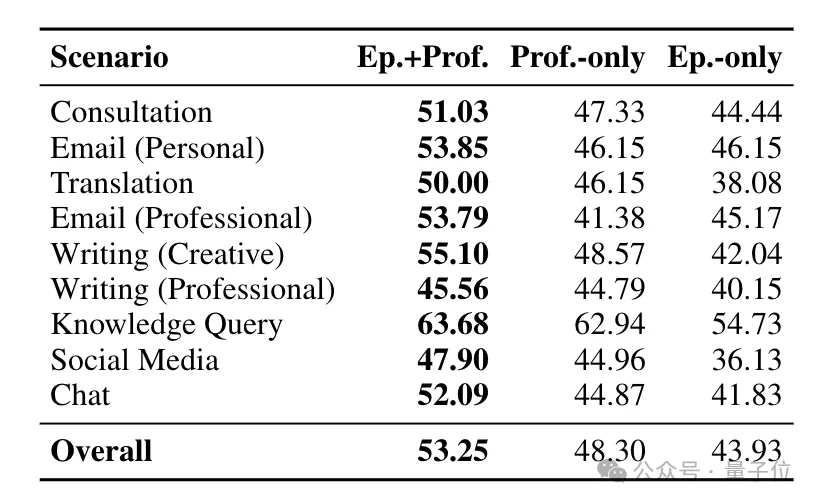
足以见得,EverMemOS是相当全能的一枚选手,记性好、搜得准,关键还运行速度快、成本还够低,最长可突破百兆上下文限制。
一边帮大模型减负,一边帮大模型补记忆力,堪称大模型版安神补脑液。



