

3月30日,阿里正式发布千问新一代全模态大模型Qwen3.5-Omni。该模型在音视频理解、识别、交互等215项任务中取得SOTA成绩,核心指标超越Gemini-3.1 Pro,跻身全球顶尖全模态大模型行列。
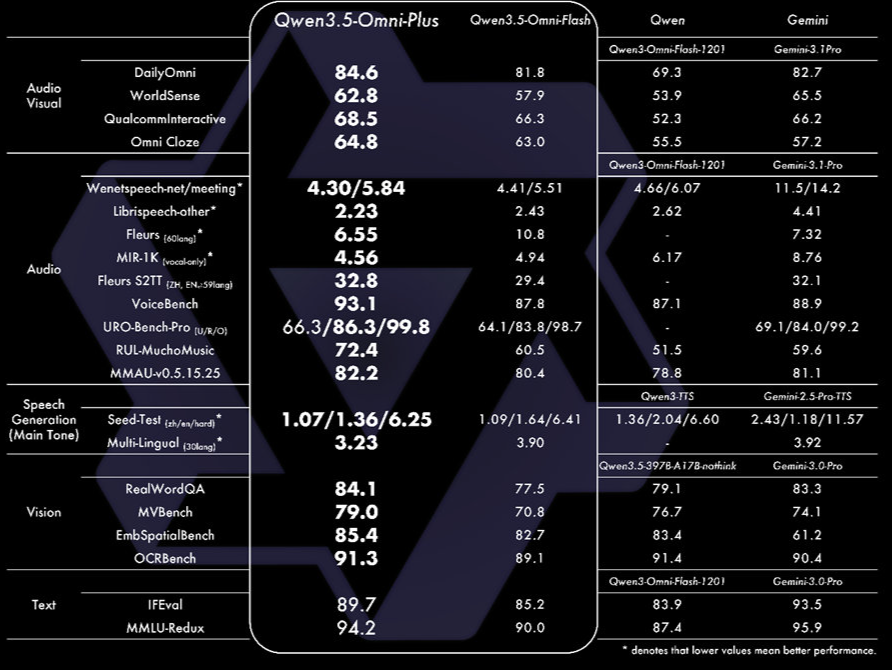
Qwen3.5-Omni采用Hybrid-Attention MoE架构,基于海量文本、视觉及超1亿小时音视频数据完成原生多模态预训练,支持文本、图片、音频、音视频全模态输入输出。其音视频理解能力可实现细粒度结构化描述,能精准识别113种语言及方言,还自然涌现出音视频Vibe Coding能力——用户对着镜头口述需求,即可生成可运行的代码。
实时交互体验也迎来升级,模型支持语义打断、音色克隆、语音控制等功能,可像真人一样灵活调节语速、情绪,还能自主调用WebSearch和工具完成复杂任务。Plus版本支持256K超长上下文,可处理超10小时音频或1小时视频。
目前,阿里云百炼已上线Plus、Flash、Light三种API规格,覆盖短视频、游戏、自媒体等场景。普通用户可前往Qwen Chat免费体验,开发者调用成本每百万Tokens不到0.8元,仅为Gemini-3.1 Pro的十分之一。



