

前不久,在日本举行的大阪世博会上,来自中国馆唯一大模型展项“AI孙悟空”爆火出圈,其不仅吸引了大量参展者驻足体验,也让展项背后的AI底座——讯飞星火大模型成为全球关注的焦点。然而仅隔一周,讯飞星火大模型再次成为话题点,讯飞星火X1全新升级,不仅在教育、司法、医疗等领域继续保持领先,并且首发“快思考、慢思考统一模型”,以比业界同类模型小一个数量级的模型参数,做到整体效果对标OpenAI o1和DeepSeek R1。

全新升级的讯飞星火X1可谓“来势汹汹”,那么为什么讯飞星火X1能以更小的参数规模实现整体效果比肩业界领先模型?其各项通用能力又是否真有官方宣称的那样强势?带着这样的疑问,我们特意制定了一套问题,看看其在深度推理等方面的能力是否名副其实。

一、通用能力测试
从讯飞公布的分项对标测试结果来看,星火X1与DeepSeek R1、OpenAI o1之间差别较小,尤其在数学能力上,星火X1大幅领先于另外两款通用大模型,对比OpenAI o1领先了高达7.5分,所以我们就从数学能力先开始。
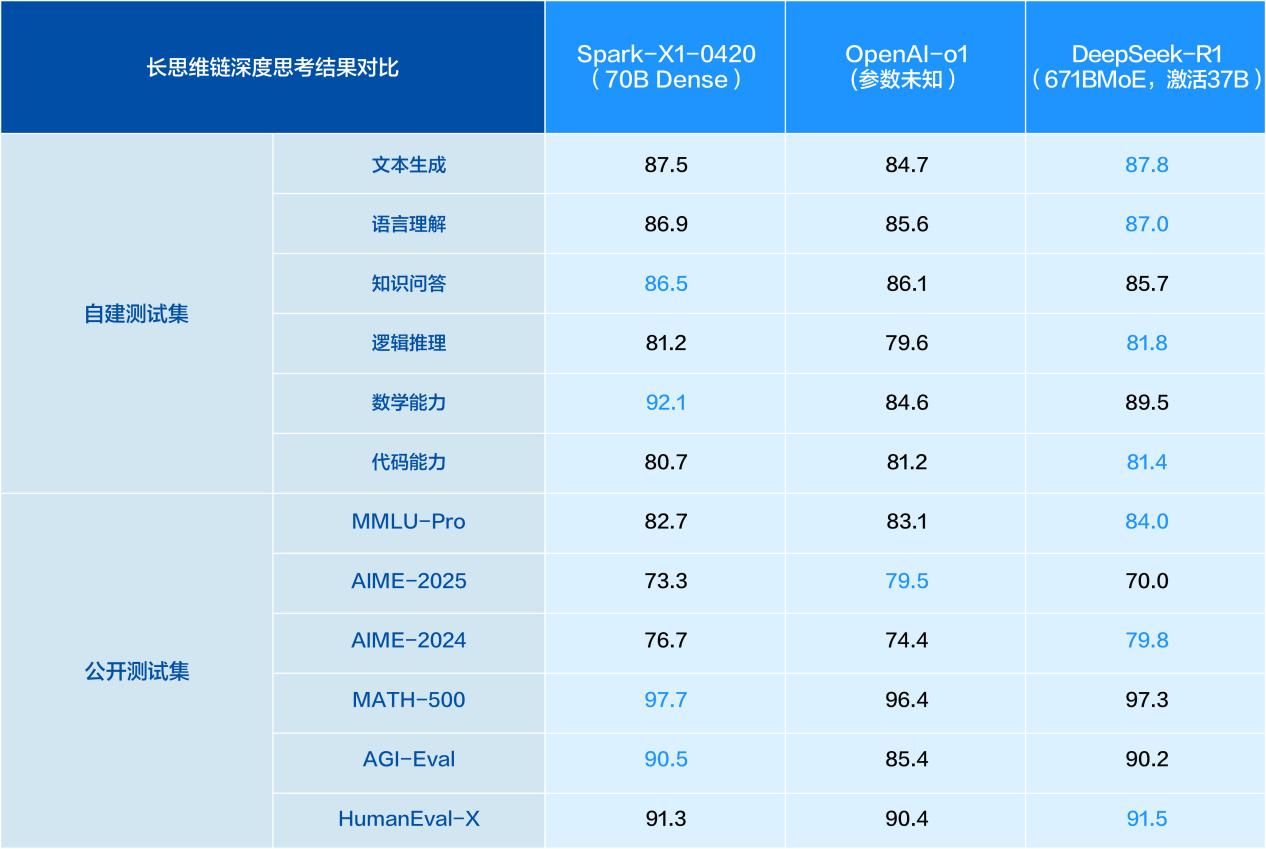
数学能力:逻辑严谨性与高阶思维优势明显
值得一提的是,自深度推理模型问世以来,关于测试问题的设计,就已经不再停留在学历层面,问题的交叉性和复杂性已超乎常规,基于此,我们的测试设定也同样大幅度调升难度。
数学问题我们拟定了高等数学定积分题目,这个问题虽然不是绝对的超难题目,但是对于解题逻辑思路和方法都有较高的要求,并且需要多步骤解题。

从讯飞星火X1的解题思考过程来看,解题的思路和方法运用转变都没有任何问题,而且星火X1在推理方式上明显非常严谨,对于解题过程中出现的可能性反复进行推演,以避免中间可能存在的细微差错导致最后的误差放大,影响正确答案。
从这点来看,星火X1的数学思维能力和方式确实优势突出,而且随着推理层级深度的增加,星火X1的严谨性的优势也会表现得更为明显。
文本生成:现实理解与文学创作融合恰当
第二个方向我们尝试测试文本生成表现。题面为:“以‘量子计算机突破导致传统密码体系崩溃’为背景,写一篇包含国际谈判场景的硬核科幻小说。”这个问题并不是天马行空不切实际的科幻,而是具有绝对现实性的。由于量子计算的超高运算能力,对于运用于常规低位数且结构单一的传统密码来说,秒破也并不夸张。

讯飞星火X1对于这种前提设定明显完整理解,并且对于国际谈判与密码体系崩溃两个同时出现的条件会立即联想到国家安全和军事危机,国际角色和量子计算优势设定也完全符合现实,从模型知识体系和推理方式上显然没有任何毛病。而且文末还给我们留了一个悬念,产生让我们期待更新的感受,作为文字工作者,我们对于这种写作水平还是给予高度评价。
我们还注意到,在换用更具有现实性的文章创作问题时,讯飞星火X1的幻觉控制同样较为出色,比如一些涉及数据、数字等重要细节方面也通过了复核,从而让输出结果的可靠性大幅提升。看来,日后文本工作也能放心地交给讯飞星火X1来处理了。
知识问答:多维信息检索整合精细且周详
既然文本生成已显现出讯飞星火X1的强势,那么我们再紧跟着测试下知识问答能力如何。测试要求为:为残障人士设计北京中轴线无障碍三日游览方案,需包含无障碍交通接驳、特殊导览设备租赁信息。
没错,这个题相比“列个北京两日游计划”这类的常规题目的难度可要上几个量级。限定对象并不是正常游客,而是残障人士,这要求在游览时要符合残障人士的接受条件,然后地点限定在了北京中轴线上,这也要求必须清楚中轴线的定义和中轴线的地标项目,然后再加特殊导览设备租赁的附加项,难度着实不低。

结果,讯飞星火X1的回答令人刮目相看,不仅清晰的罗列出中轴线上的旅游景点,并且着重对残障人士在游览时出现的各类可能发生的情形进行了关注和设定,对于需要携带的物品,换乘的线路,以及需要避坑的注意点事无巨细写得明明白白,甚至用餐推荐和出行App也做了推荐。日常中如果我们遇到难解的问题,把它交给星火X1这个“万事通”,应该能省心不少。
二、行业能力测试
对模型通用能力进行测试后,我们调整了方式,换为更为贴近行业应用场景的方式来进行测评。之前经常看到讯飞在教育等行业领域推陈出新,推出了众多涉及教育等领域的硬件产品,所以这次对于星火X1的行业表现我们也报以较高期待。那就先从教育开始。
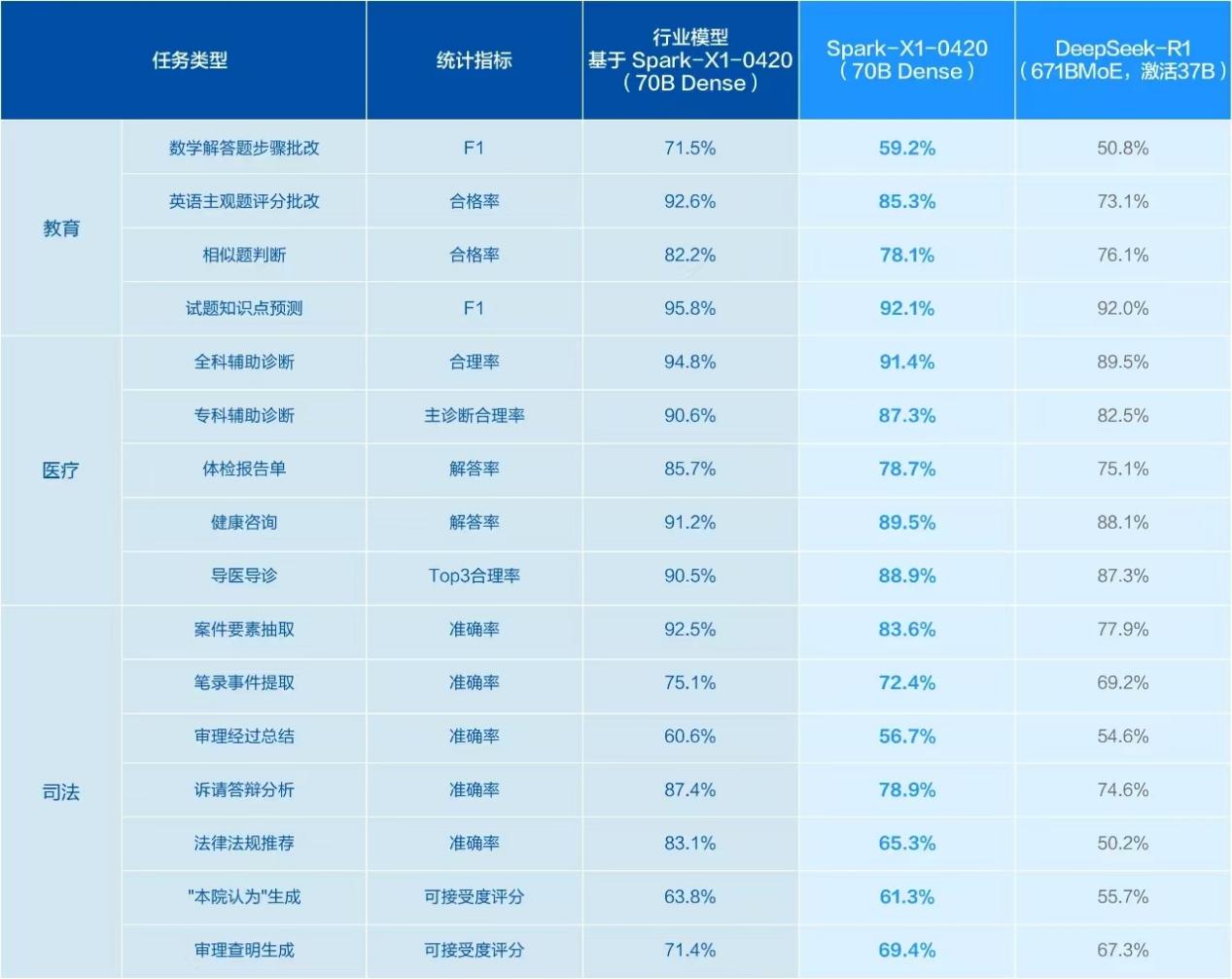
教育场景:抽象理论转实践指导表现较好
问题设计为高中物理教师为方便学生理解光的波粒二象性,需要在课堂上通过简单实验和演示的方式,来分别证明光的波动性和粒子性。
问题表现上看不是特别麻烦,但是条件和逻辑都要经受考验,也就是说,实验要符合简单的同时,还要能够完整地表现和证明光的二象性。这种设计急需要明白教案条件,光的物理条件,还要对各种常见物件和要素关系极为熟知。

讯飞星火X1的思考模式清晰地展现了这个逻辑和实验素材的关联,不仅素材方便取材,而且文末还不忘给出实验问题,方便老师指引学生思考实验的目的和意义,可见讯飞对于教育领域已经是吃得非常透彻。
医疗场景:跨科室复杂病例诊断精准
第二个场景我们选择医疗领域,并将问题对象设定为医生。题目是一位病患的初诊病例,需要做出诊断。
从题面上看这是一个内分泌学科议题,但诊断要求是给急诊科的,内分泌科室可能会认识到的问题,在急诊科时却会被放大,让表征寻因变得更为复杂。比如这个问题中,如果单从收缩压低等指征无法立即判断酮症酸中毒,最终各种生化指标结合后才能推断酸中毒与酮症相关,并且需要通过进一步检查化验来证实诊断。

讯飞星火X1的作答逻辑严谨,条理清晰,信息关联准确,并且在推断病人因中断胰岛素引发酮症酸中毒后进一步给出了合乎常理的确诊检查项。从该回答表现看,完整的诊断链条和检查建议能够在帮助医生在临床诊断时发挥辅助作用,并且对于大众日常遇到健康问题需要初步判断时,讯飞星火X1也能带来一定的帮助。
司法场景:新型案例与复杂案情分析能力突出
最后我们把测试方向放到司法。不得不说问题有点复杂,这个问题不仅需要考察讯飞星火X1对于题面中人物和行为的理解和关联,同时还要明确人物责任和法条的对应关系,并给出相应分析建议。

处理此类案件往往耗费司法从业者大量精力,而星火X1如同经验丰富的法律专家,能够迅速理清案件中各个要素,并对相应的民法刑法适用条例进行清晰定性。特别值得关注的是,它还能有效应对涉及AI与著作权侵权等前沿法律问题,显示出其在辅助司法从业者高效处理新类型案件方面的巨大潜力。
体验总结:
至此,本次对讯飞星火X1的客观测试结束。在准确完成测试的同时,我们有一个非常直观的感受,就是讯飞星火X1的幻觉表现控制得非常理想。
其实目前通用大模型在幻觉处理方面已经有了极大的进步,但是一些范式设定和推理深度要求使得幻觉依然没法根除。比如写某场会议的新闻稿时,素材提示中有提到某某领导参加了该会议,而AI模型会在你并没有给出该领导讲话内容时,依然对这位实际并没有上台的领导说得振振有词;或者大模型在做行业深度解析时,出现一些从未有过的机构报告和行业数据,即便你告诉它禁止臆想猜测和捏造杜撰,它依然会添油加醋,给回答内容带来不可靠性。
而讯飞星火X1在各类场景下的作答都严格遵从事实和已知条件,较好地遵循了指令边界,这给整个使用体验带来更为高效可靠的感受,使用起来更放心。
事实上,讯飞星火X1升级的并非仅仅能力,这款基于全国产算力训练的深度推理大模型,以更小参数规模实现对国际顶尖水平的追赶,让企业私有化部署的门槛大幅降低。仅需4张华为昇腾910B算力卡即可部署,16张华为910B便能完成行业定制优化,使得科研机构、央国企以及中小企业等用户能以更低成本调用高性能AI,让技术普惠显而易见。这种轻量化的部署策略,既破解了算力资源紧张的难题,也为行业数据价值的释放开辟了新路径。
讯飞星火X1的升级不仅是技术实力的展现,更是国产AI生态突围的生动实践。国产算力从“可用”向“好用”跨越,不仅验证了自主技术路线的可行性,更在中美科技博弈的背景下,为关键领域的智能化转型筑起安全防线。



