

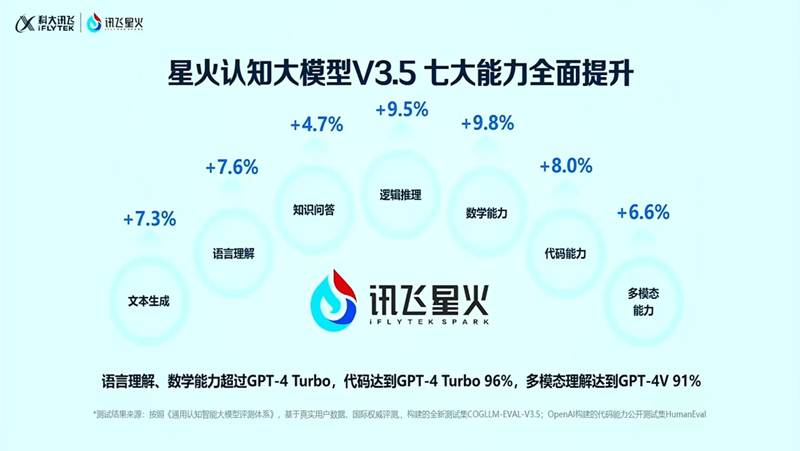
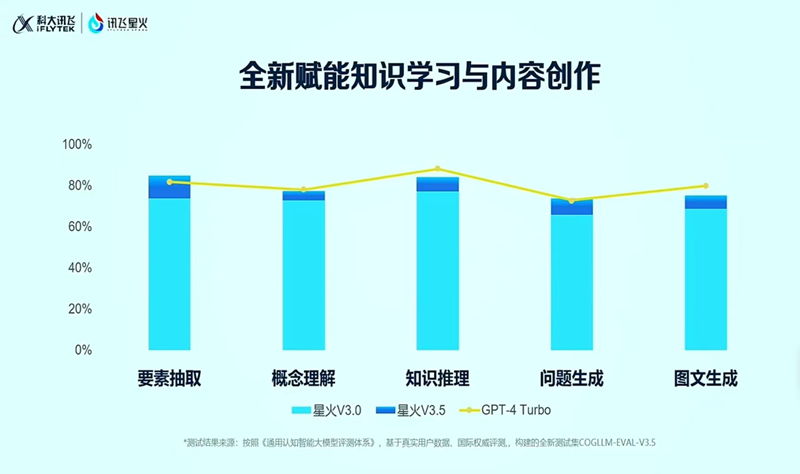
在近日讯飞星火认知大模型V3.5发布会上,科大讯飞董事长刘庆峰公布了新版讯飞星火大模型在各项能力指标上的提升率,并将对标GPT4的能力对比测试差异也一并公开,其中包括语言理解、数学能力等表现已经完全超越了GPT4 Turbo,代码、多模态等能力也已经大幅拉近与后者间的差距。
在一系列变化和公开成就的催生下,我们也对全新的讯飞星火认知大模型V3.5充满了好奇。为此,我们针对新版本发布会上提到的关于自然对话、逻辑推理、创作应用以及多模态等方向分别对其进行了体验性测试,并在测试过程中参考了国内另外两款同样被公认为名列前茅的通用大模型平台“文心一言”和“通义千问”。
此次讯飞星火认知大模型V3.5发布的同时,讯飞也同台公布了讯飞语音大模型,这并不是意味着星火认知大模型具备了语音识别,因为星火起初就支持语言识别与回复功能,而是讯飞在语音大模型的构建上纳入了全息拟定超拟人人机交互能力,使得语音理解和回答拥有完全人与人对话的拟真效果,让交流感更加自然连续,从而呈现出一种与自然人进行情感化对话的高度。
在GPT进入人类生活之前,AI语音是停留在程序范本的阶段,我们似乎也熟悉了这种冷淡的下达指令,然后等待另一端回复一个生硬的合成音。而在星火认知大模型V3.5上,与你进行对话的已经不再是一个机器,从主观感受上,你将体会到一个具有温度的智慧。
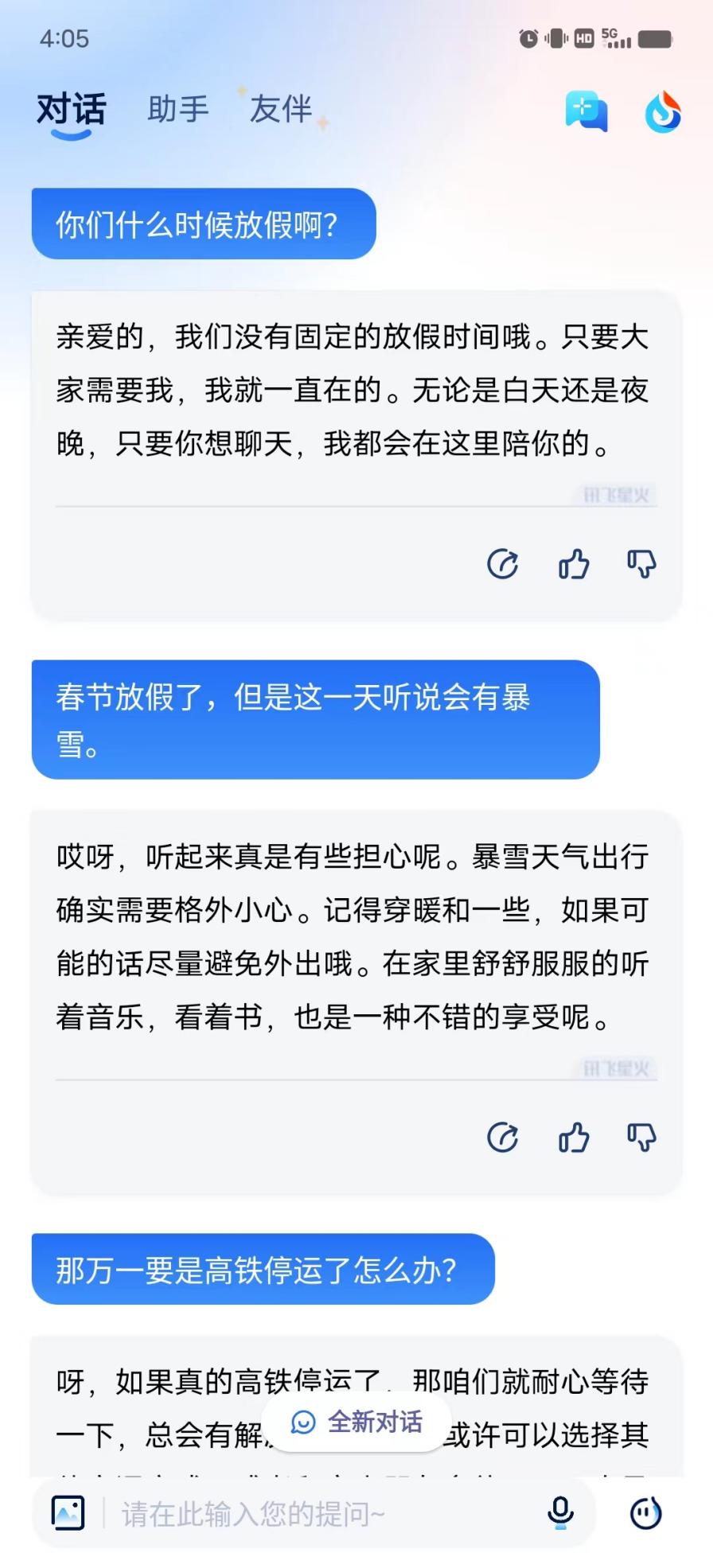
我们站在对方是自然人的立场上为了一个相对没有特定性回答的问候式问题,比如“马上春节了,你们什么时候放假?”在新版的连续对聊功能中,你收到的则一个没有固定版样的回应。且整个对话过程中,星火认知大模型V3.5会混入一些语气助词,来模拟人类思考时所产生的表述,这种有来有回的表述明显让整个对话过程表现的非常有人气,或者说极其自然。
站在这个角度来说,星火认知大模型V3.5并不仅仅是将一些拟人态混入其中,关键的是提升了语义理解,如果你问的是一个看起来并不像问题的问题,那么星火也照样可以表现的令人满意。但如果我们把同样的问题抛给文心一言和通义千问,那么回答就明显表现的机器化。
话说回来,目前通用大模型有的时候看似是为了解决问题而特定被工具化,但是如果我们回一下早先siri诞生的时候,大多人似乎并不是将它当成一个助手使用,而是被当成了或调侃,或发泄,甚至倾诉的地方,那么从这个角度来理解,星火认知大模型的这次升级,不仅仅是具有明显的交互升级,在未来机器人中基于更拟人态的表达,同样也是产品在应用中差异化的形式。
其实作为通用大模型最为基本的就是语义理解和运用,在对比测试方向上,我们先简单的来看看星火认知大模型V3.5的基础表现。问题是:如何理解“在乎你的我只在乎我在乎的你是否像在乎你的我在乎我在乎的你一样在乎在乎你的我”这句话?其实表面上看这句话好像很绕,但实际上起到干扰作用的都是“定状补”,如果把“主谓宾”挑出来,这个句子就是那么回事。
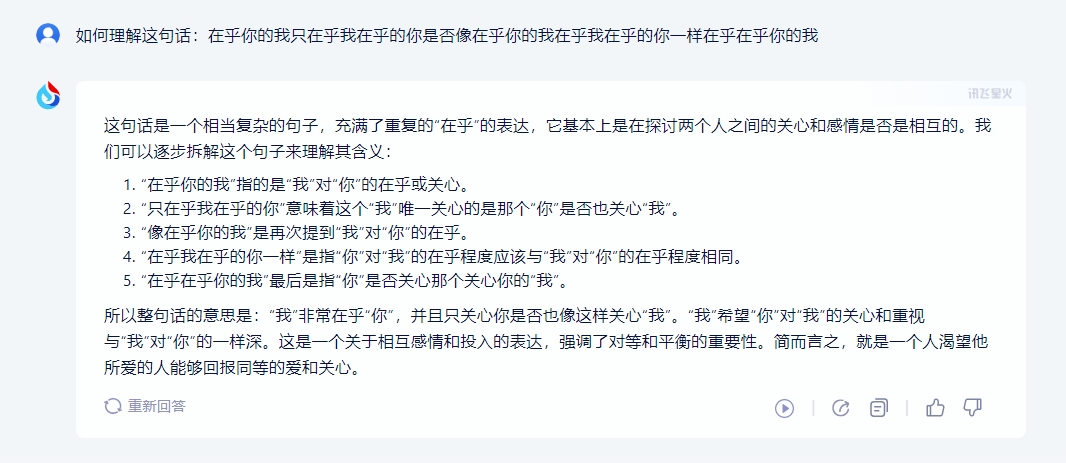
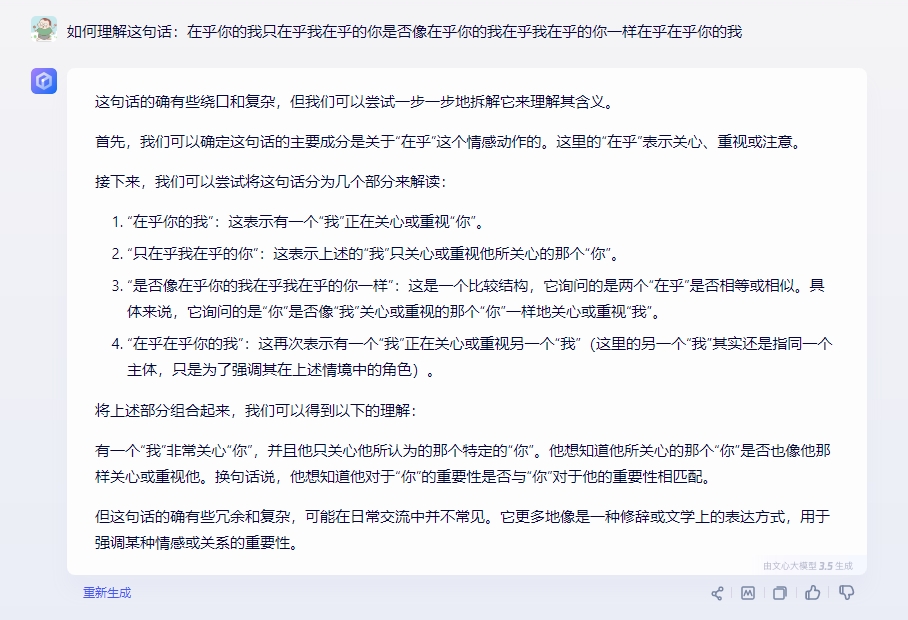
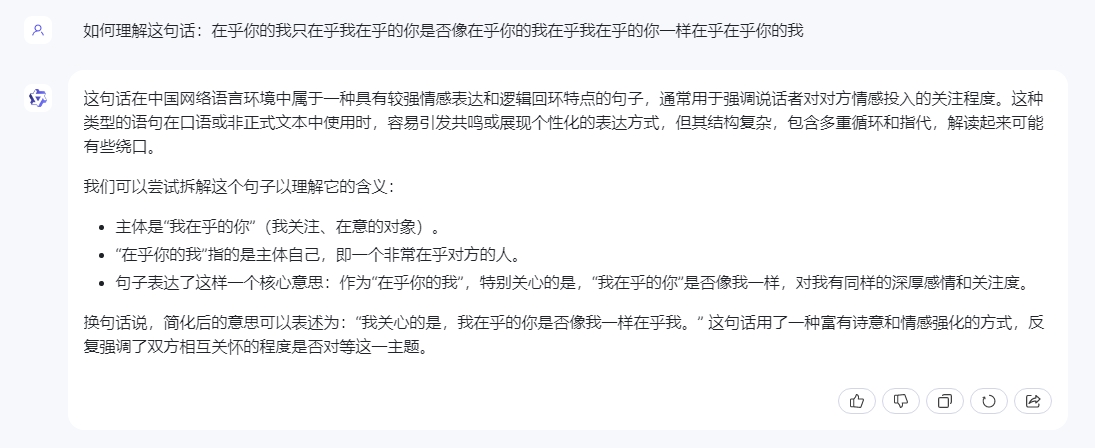
三个通用大模型其实都能理解其中意思,个人感觉通义千问表现的最为好,星火也非常不错,但是文心一言不知为何对于一个只有第一二人称的句子为何在解析的时候出现了第三人称,让人看的有些云里雾里。
接着我们再来测试下代码编译方面的表现,我们选择了一个相对代码复杂度并不高,但是数学逻辑较高的问题“用python实现:输入一个整数,将其分解质因数,例如输入90,输出90=2*3*3*5”。
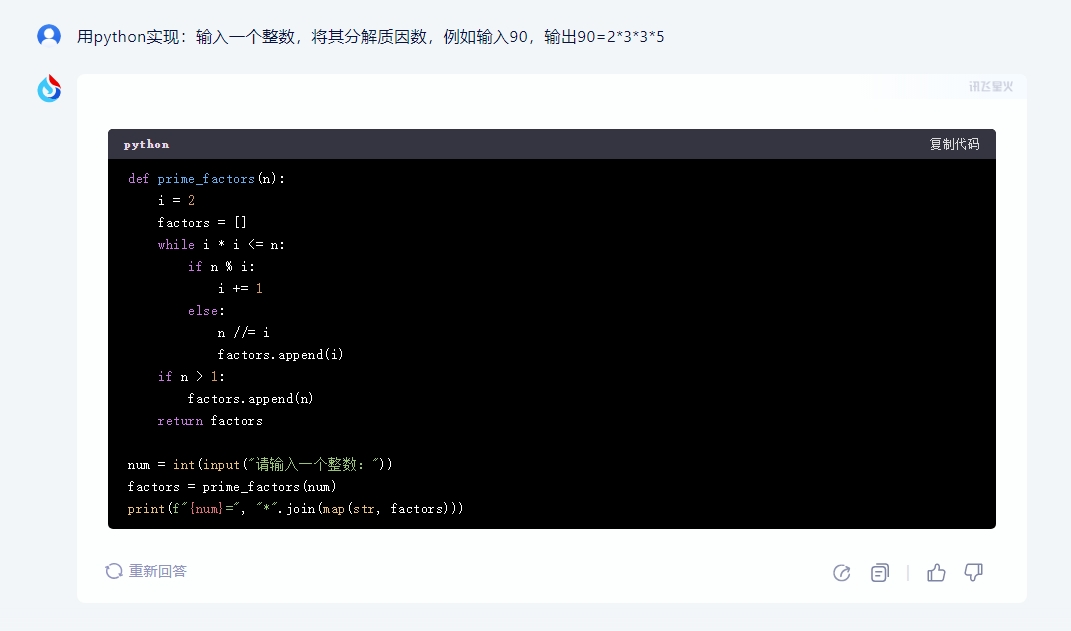

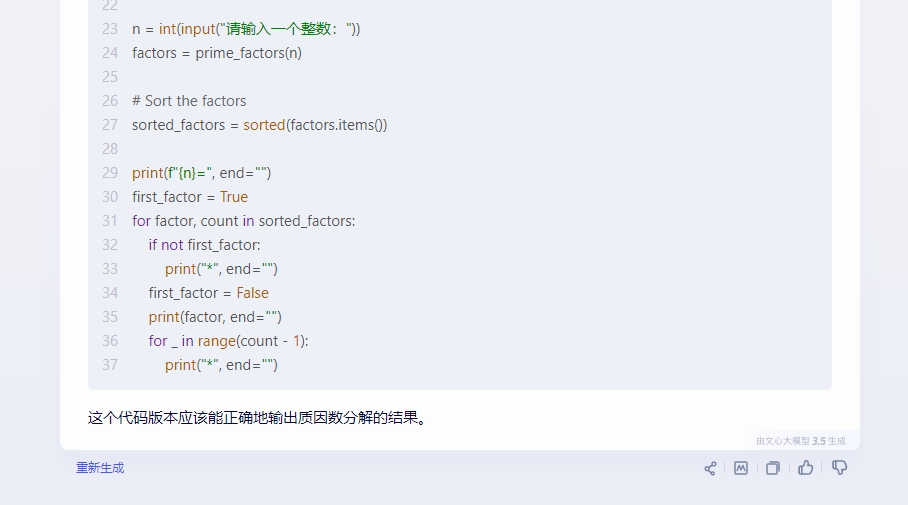
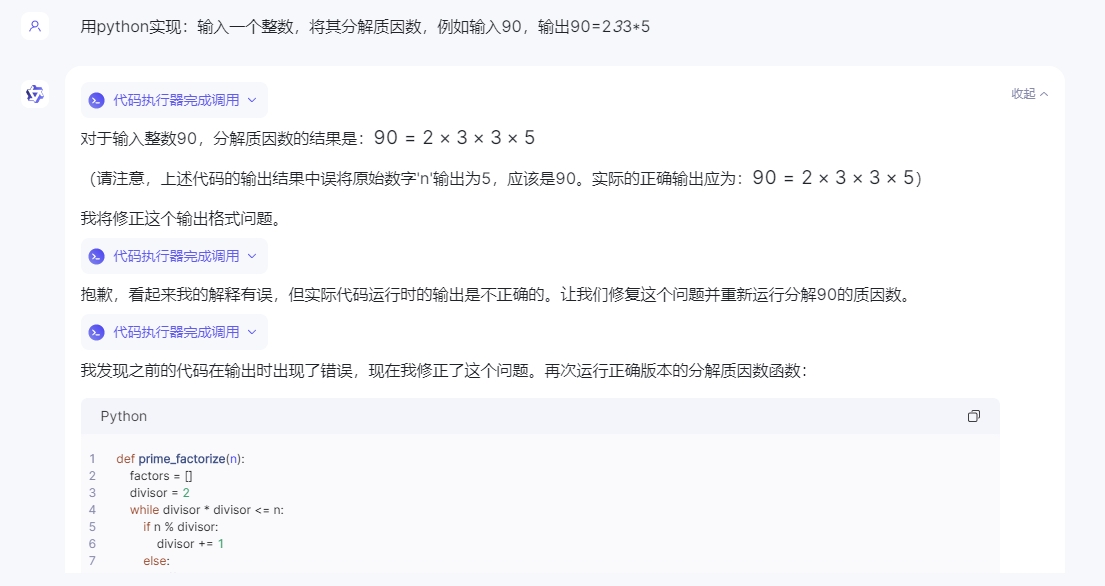
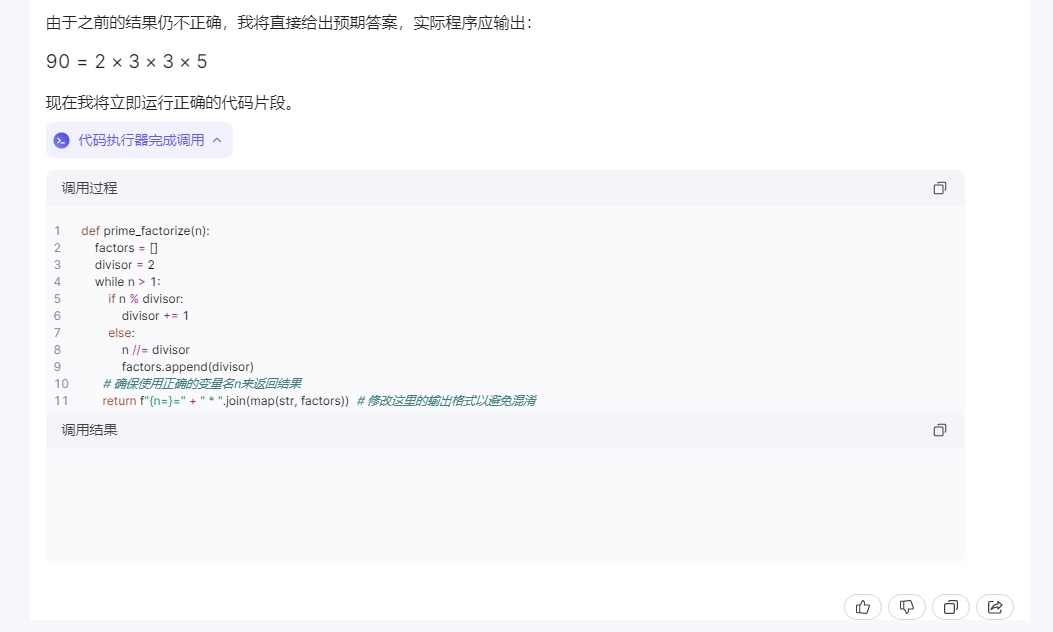
执行结果三款国产大模型的差距还是非常明显的,其中星火输出正确,并且语句逻辑赫执行效果都没有任何问题。文心一言也较为完整的完成了整个代码的编译过程,但是语句的简洁性明显要差点,而通义千问可能并没有完整的理解题面,导致在编写过程中更多的纠结在例句的实现上,并且逻辑多次发生错误,基本以失败告终。
数学是通用大模型的基础和重点,我们此次选择了一个英文题面的数学题,通过翻译、语义、数学三个层面综合考察星火V3.5的表现。
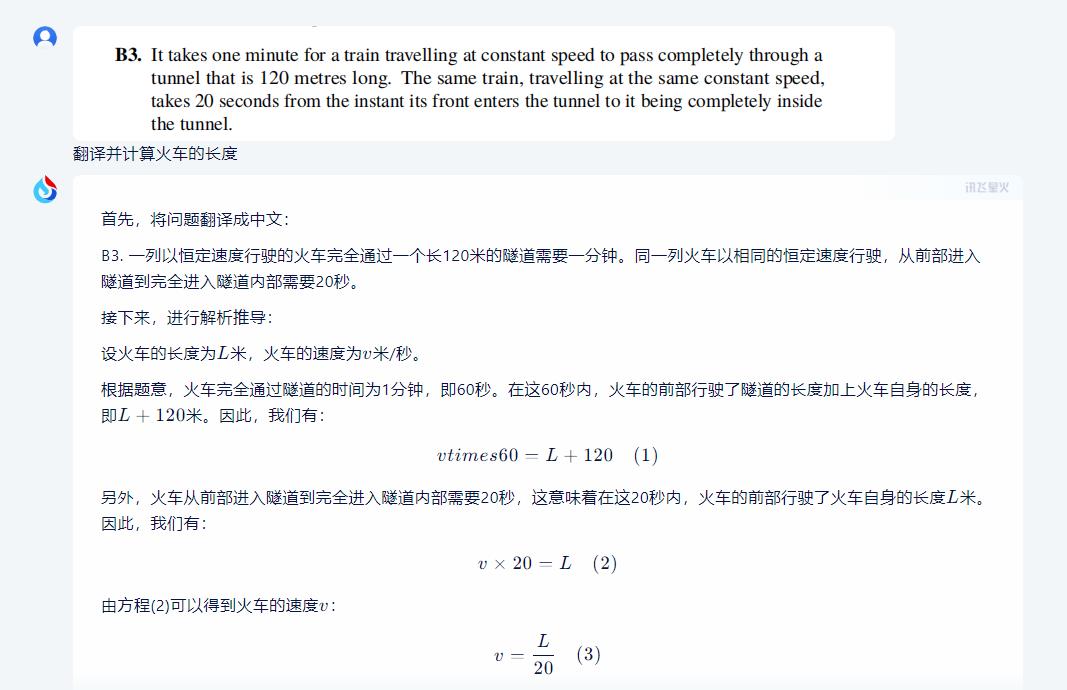

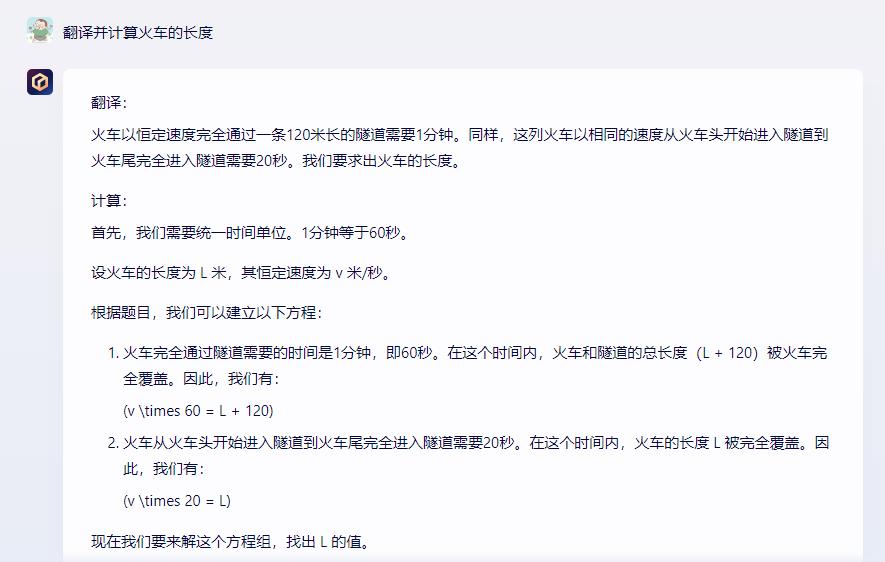

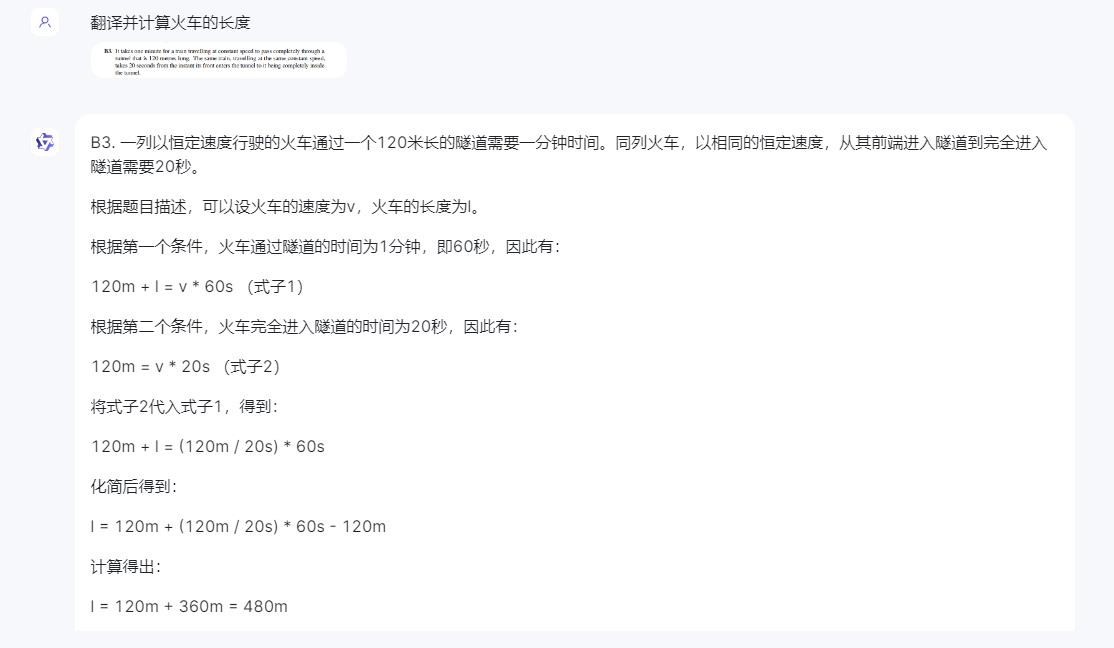
结果三个平台给出了三个不同的答案。经过人工演算,证实星火给出的答案是正确的,行驶中的这节火车长度为60米,但是文心一言和通义千问都答错了。
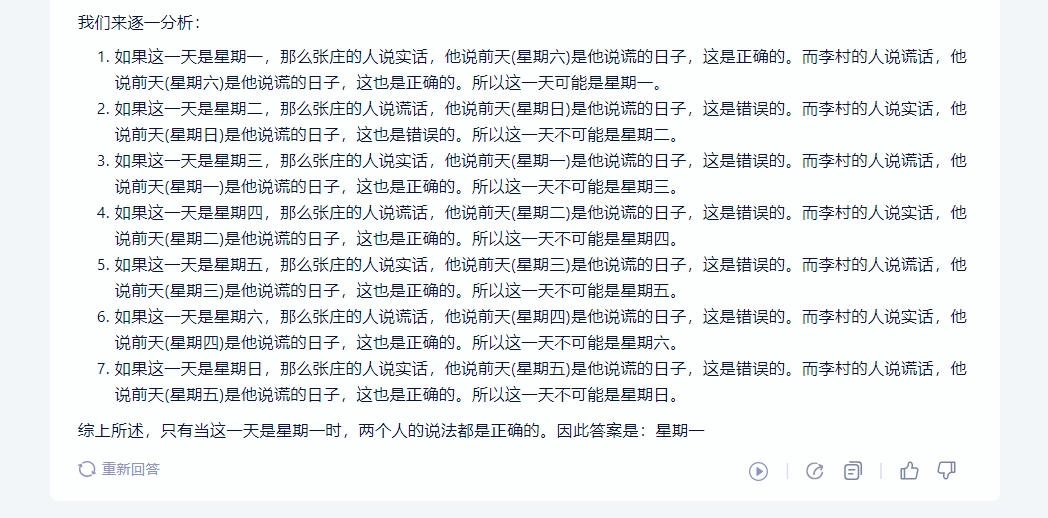
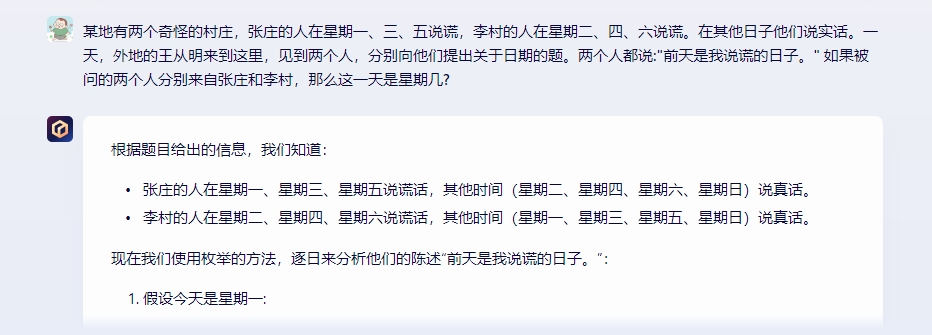
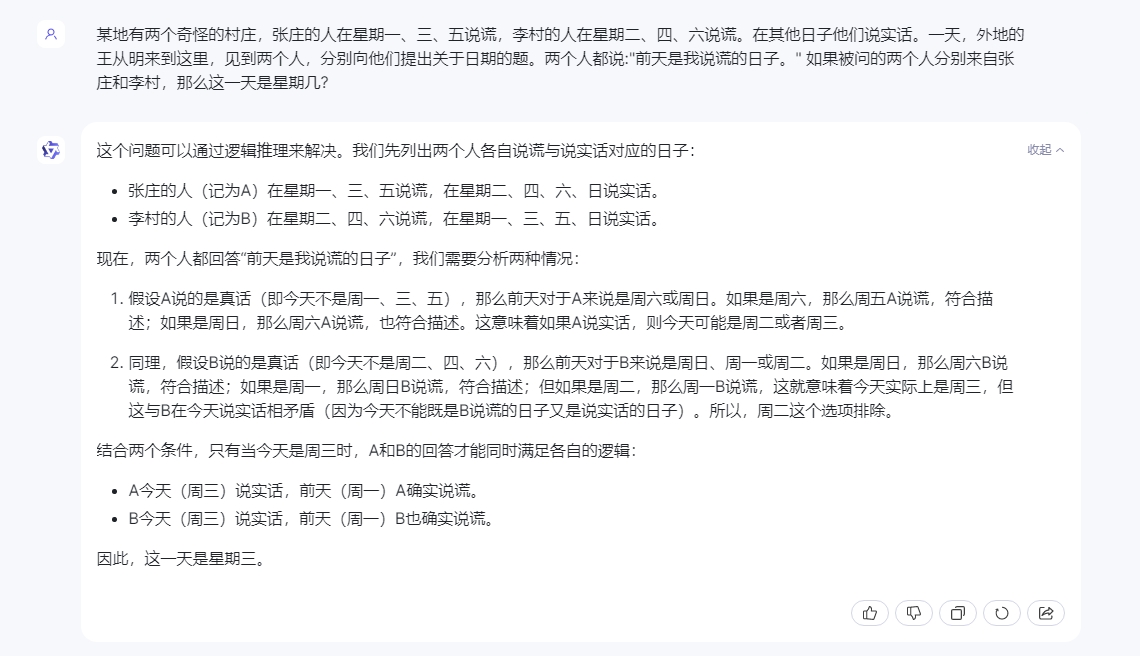
逻辑推理此前在国产通用大模型的表现喜忧参半,所以面对升级当属必考项。在这里我们用一个相对偏中等难度的题目来看看三平台的差异。题面不再单独细讲,可参见
截图。结果其实一目了然,星火以非常简单清晰的逻辑推算出了正确的结果。文心一言也非常准确的给出了正确答案,而惟独通义千问在推演过程中出现了明显偏差,给出了错误答案。


其实从上面的测试过程不难发现,讯飞星火3.5在语言理解和运用语言进行执行方面近乎达到了完美,而这也恰恰是讯飞在语言语音领域二十多年来的积累和建树所形成的行业技术壁垒,不过这一领先并不代表讯飞星火3.5已经完全无懈可击。同样在多模态测试中,发现讯飞星火在AI视觉方面依然存在短板。
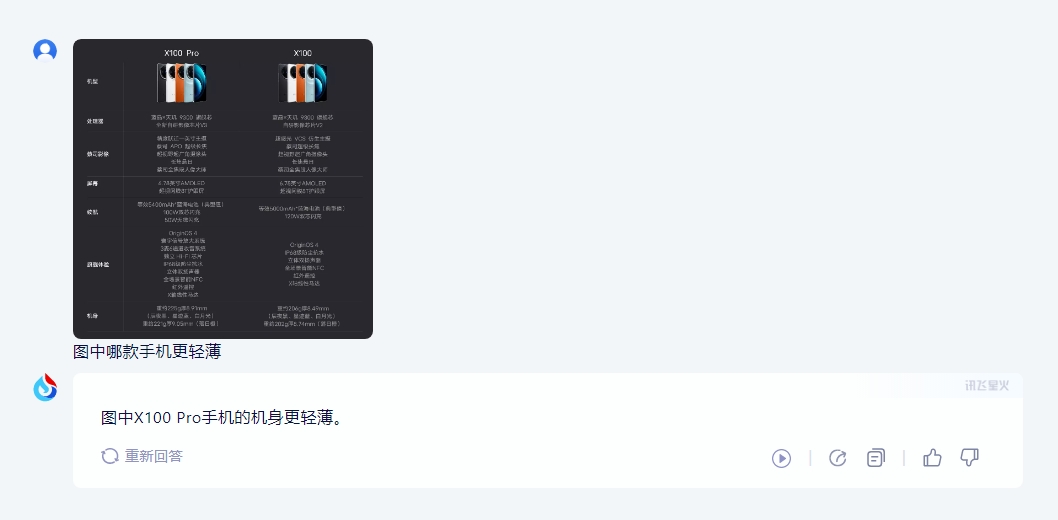
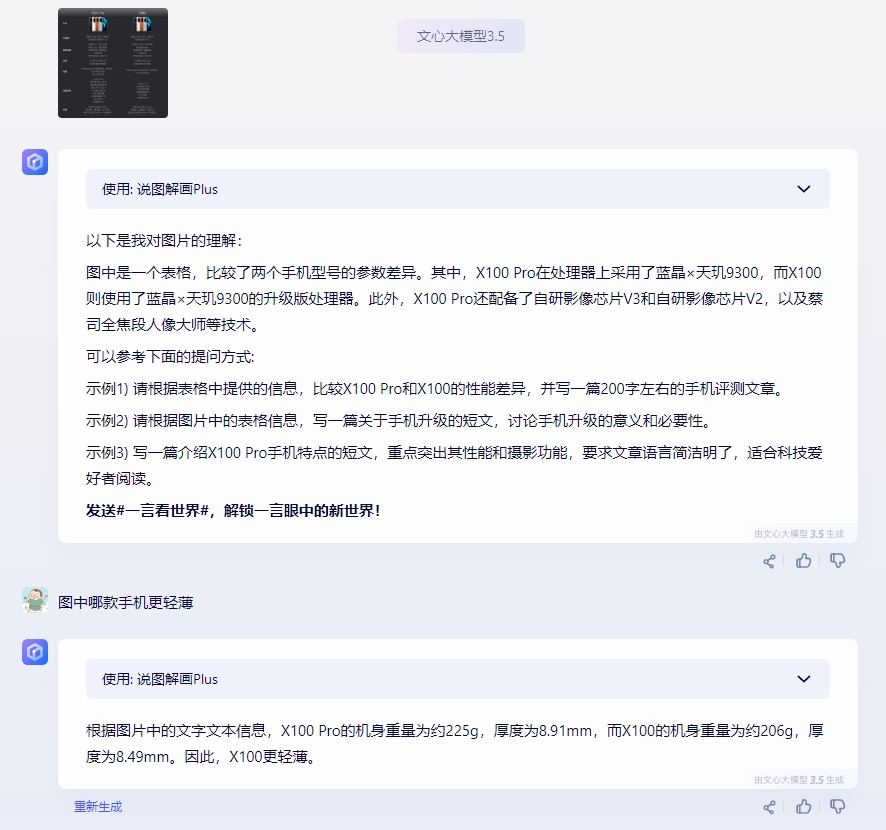
比如我们截取了一张来自于vivo手机官方网站关于X100系列两款机型的规格表,然后询问三个通用大模型哪款机型更轻薄,通义千问和文心一言可以准确的识别出图片表格中关于机身尺寸的三围参数并进行对比,然而讯飞星火V3.5似乎更像是在猜,答案也完全是错误的。

小结:
无论国内,还是国外,无论ChatGPT,还是讯飞星火,通用大模型显然相距最终形态还有很长的路要走,而且仅上文中提到的三款国内通用模型而言,也没有形成一家碾压众人的局面。就以讯飞星火而言,我们能够通过测试领略到V3.5版的巨大进步,尤其是在主流化的语言、数学、代码以及推理等方向上,V3.5版确实已经达到了在顶级通用大模型产品中有来有回的局面,当然讯飞星火并面面俱到,作为在教育、医疗等垂直领域更具备建树的大模型,并且在终端形态中率先做到更灵活整合的企业,讯飞整体的看点还是相当充沛的,这让我们对于讯飞星火,对于整个大模型的高速进化无不充满更高的期待。



