

三万多字的行业报告,九十余条的合同细则,一百多页的技术白皮书,一小时的采访录音,两小时的会议视频……当你在日常的工作与学习中遇到这些材料时,你会怎么做?如果按照以前的处理流程,必然是先口吐芬芳抱怨几句,然后硬着头皮按部就班的从头到尾提取你需要的信息。
事实上,“太长不想看”已经成为了快节奏生活和海量信息时代交织后人们最为典型的心理特性,不仅仅是刚才提到的那些枯燥乏味的内容材料,哪怕是长篇小说、娱乐视频等等本身兴趣方向浓厚的内容,也同样开始遭到不耐烦的对待。

然而,伴随着科大讯飞星火大模型V3.5功能上新,这个痛点终于要被解决了!
近日,科大讯飞针对星火大模型V3.5版新增了多项“杀手锏”级功能升级,其中包括了对长文档、长图文、长音频和视频的支持,可以快速精准解析上述材料内容,用户可以直接以问答形式提炼内容并获取自己需要的信息,大大提升工作和学习效率。接下来,不妨跟随我们的测试一起来了解一番。
长文档测试:海量文本高效解析 革新传统处理方式局限
从ChatGPT开始进入大众视野起,通用大模型基本上是依照对话式的交互思路发展,但是token能力在很大程度上限制了应用场景,即便国内有大模型平台已经开始支持文档功能,但是依然存在诸如文件体积以及解析识别能力上的束缚。
星火V3.5版在长文档方向上的先进性不仅仅是在于支持的文档体积已超越常见规模,并且星火V3.5兼容格式以及处理效率、精准度等方面也堪称首屈一指,可以很好的兼容PDF、Word以及TXT等多种文本形态,操作体验上也更为简便化。
测试样本我们选择了一份由国家生态环境部和国家市监总局共同颁布的《汽油车排放物限定值及测量方法》,文件号为GB18285-2018,通俗点说,这份文件就是现行的汽油车新车下线和在用车年检尾气排放检测国家标准,整个国标文件共126页,文字数量长达几万字,如果按照常规的检索阅读方式,学习和查询都会耗费大量时间。
但是,通过星火V3.5的解析后,无论查询数据还是总结要点都轻而易举。
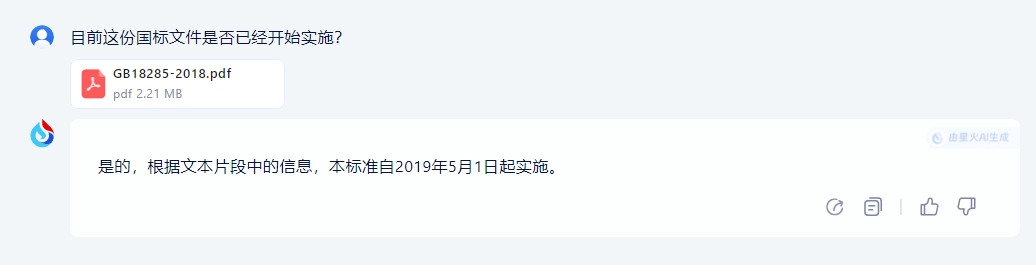

测试过程中,我们先询问星火这份文件是否已经开始实施,显然在第一页较为明显处已经标注了新版尾气国标检测的印发和实施时间,所以星火给出的答案无误,而且从中可以看出,星火可以依照文档信息与当前时间进行综合获取和比对判断。


随后我们开始加大难度,询问星火新版国标与早先版本存在哪些修订之处,这个问题看似简单,但隐藏着模糊之处,那就是啥叫早先版本?所以需要大模型拥有一定理解分析能力。不负所望的是,星火完整的给出了新版文件的修订内容,并清楚的依照文中信息罗列出来。


那如果我要查询数据呢?随后我们询问有关检测限值指标的问题。同样星火能够依照引导给出全面的答案,包括一氧化碳、碳氢化合物以及氮氧化物在不同检测类型下的合格数值。
可见,单纯的文本检索性提问显然难不倒星火大模型V3.5,所以我们准备再提升一个难度量级,换英文版的文档。
第二份测试样本则是一份来自Winbond有关SPI NAND存储芯片的datasheet,这份文本不仅通篇英文,并且包含了大量专业术语,如果我们用中文提问,不仅考察了星火大模型V3.5对于英文长文档的分析能力,同时还要对中英文关于专业词汇和互换理解等硬指标提出要求。


首先最简单的问题是有关于芯片的工作电压,然后是有关存储器的写入流程、指令以及注意事项,没想到的是,整个测试同样让我们喜出望外,尤其是关于注意事项部分,星火大模型V3.5准确的总结了文档中有关SPI NAND注意读写周期等待的问题,着实令人刮目相看。


其实长文档的应用不仅仅限于我们现有的测试方式,它还可以应用到商务场景中,比如合同的检阅,厉害之处就在于其融合了法条逻辑判断,与星火合同助手融为一体,可以帮助用户审查合同的严密性,是否存在对某一方不利的情形,从而有效的完善合同,避免出现纠纷。
另外,它本身支持多份文件输入,这就意味着其同样拥有文件比对功能,尤其是在招标等场景下,可以实现智能审标的功能,检查投标方是否提交了完备的资质证明,以及在某些细节上是否具备资格等,可以有效的减少人工核对的工作量。
长音视频测试:业界首发 录音、视频不用转文字便可即问即答
这部分功能可以算得上是星火大模型独一无二的能力,目前国内先行的通用大模型平台均限于图像与文字,音视频内容作为问答素材目前也仅有星火大模型V3.5。而且该功能的文件支持范围极宽,不仅包含常规的MP3、MP4、AVI,而且还有WMA、WMV、RMVB、MOV、M4A等音视频格式,可以说目前常见的录制设备输出格式全部囊括在内了,如果不考虑码率等质量问题,时长在2小时以上显然不在话下。
音频文件我们选用了此前采访过某企业高管的录音,整个录音长度约20多分钟,因为是展会,声音相对嘈杂,还是比较有挑战性的。
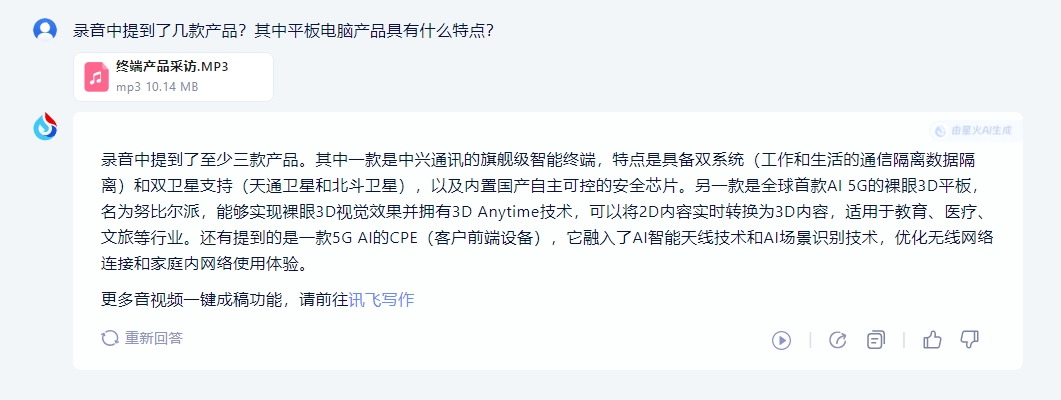
提问方式依然是由简至难,首先是关于采访中提到了哪些产品,星火V3.5不仅清楚的给出了三款产品的型号,同时也总结了各个产品的特性。
既然如此,我们直接用视频为素材,让星火V3.5来一篇关于其内容的新闻稿,而且还要带行业分析的那种,结果当然是没有问题的,而是通过这个演示我们能够看出,无论文档还是音视频,本身素材就已经是问题的材料和方向,这对于生产答案给出了更多便捷性和可能性。
视频测试我们使用了一段大约5分钟的采访视频,素材的质量与录音大致相当,并且受访者有一定的地域口音,但识别效果无疑是优秀的,通过抛出总结性的问题,星火V3.5同样给出了精准的答案,并且还给出了讯飞写作,一键成稿的功能指引,似乎星火V3.5也猜到了我们的工作属性。

值得一提的是,不只是回答效果突出,在素材处理的效率上,星火V3.5也表现的非常出色。大体积的文档和音视频文件在上传后便可以直接开始提问,完全不需要等素材识别处理的过程,而且即便在问题给出后,整个回答的耗时也并没有比早先纯问答的形式慢多少,无需长时间的等待,星火V3.5便高效给出答复。
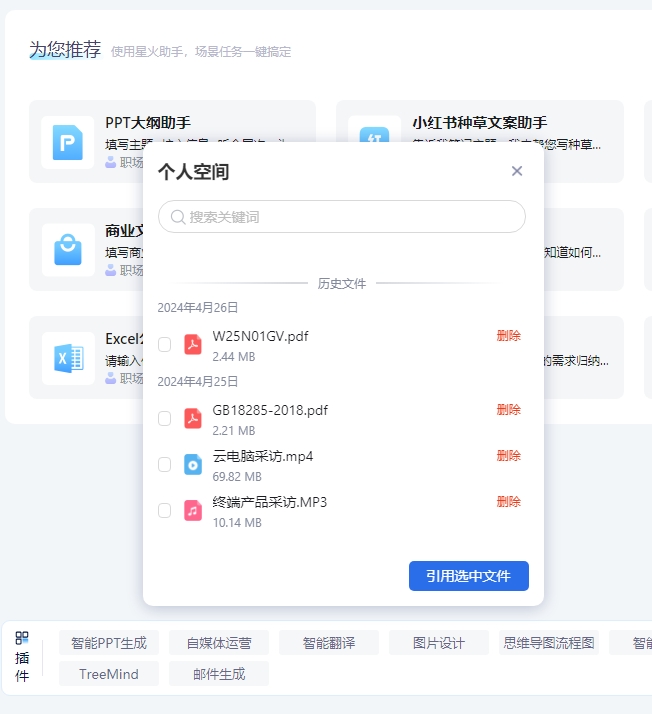
另外不得不说的是,为了能够支持素材的传输和利用,此次星火V3.5还特意在大模型中提供了个人空间功能,也就是说,我们所上传的文档和音视频可以直接保存在云账户内,无论是需要日后继续查阅分析,还是更换到另一台终端上,这种个人空间的设计形式都提供了极大的便利性,也同样成为了目前通用大模型的首创形式。
长图文测试:精准识别手写材料 随手一拍也能随传随用
图文的意思就是包含文字内容的图片,与文档、音视频一样,是属于语言识别范畴,严格来说,长图文是先前AI视觉能力的延伸,为此讯飞单独将图文拿出来与图片区别开,成为独立的模式。
别看它只是图像识别的一个子集功能,但是应用范围和能力却明显高了一个维度。因为我们日常学习、工作中往往会拍摄大量的带有文字信息的图片,比如手机电脑的截屏,开会时的PPT,教授课堂上的板书,孩子的作业试卷,药品说明书等等,当我们需要从中提取信息并整理信息的时候,星火V3.5就能够通过强大的AI视觉文字识别和分析能力让整个过程事半功倍。

这项功能的测试,我们首先使用了目前媒体传播最为流行的一种形式,叫做一图读懂,说白了就是“太长不想看”的图文版,我们现在的目的就是把图文版重新转换回到“太长不想看”。
我们选用了某手机厂商的官宣图片当作素材,然后用指令提取图文中有关特性总结的部分。因为整个图片的层次复杂度还是比较高的,需要AI视觉在一定程度上不能被各种其他图像和背景变化所干扰,然后提取的内容确保无误才能实现内容的扩充。
最终结果显然没有任何问题,同样我们也可以直接通过指令让星火V3.5直接用图文中的信息做一篇有关该手机产品的介绍文章。
那既然提到了板书、作业、笔记这类采用手写的图文形式同样可以实现上述功能,那么我们就不妨把难度放到较高的层面,直接用已经作答的英语试卷来作为提问的素材。

我们选择了一张书写还算规范的小学四年级英语试卷进行题面和作答的评判。星火V3.5不仅可以清楚的识别手写内容,还可以正确的分辨题目和答题区的区别和关系,并且有理有据的对作答内容进行了分析阐述,效果已经完全出乎我们意料。
不过,星火V3.5的图文识别并不是完美到无懈可击,我们在使用界限不是特别明晰的表格性图文作为素材的时候,星火V3.5会有一定的识别错误存在,所以我们也希望讯飞能够在接下来的版本继续加强星火大模型在AI视觉上的能力,将表格类图文表现进一步完善,以弥补我们此次体验中唯一的遗憾。
体验总结
事实上,星火V3.5升级点不仅这几项,同时在交互的情感能力以及CRM等办公场景的接入等方面都有了全新的提升,在此我们不再过多阐述。
从星火V3.5上新后的现有能力来看,其已经不是单纯提高算力,提升token的纵向升级,而是为用户带来了应用维度和应用场景等横向面上进行了更切合实际拓宽,进而真正的解决了用户痛点,释放AI效率的结果,实现讯飞与用户双向奔赴的效果。尤其是当下利用更丰富的素材支持来完善大模型工具化的方向,让我们媒体工作者更能从中感受到星火V3.5全新升级所带来的惊喜。我们也相信,在同样面对大量文本、音视频以及图文等各类资料的办公人士、学生群体等用户,也一样能够从早先繁复的传统处理方式中解脱出来,大受效率倍增之裨益。



