|
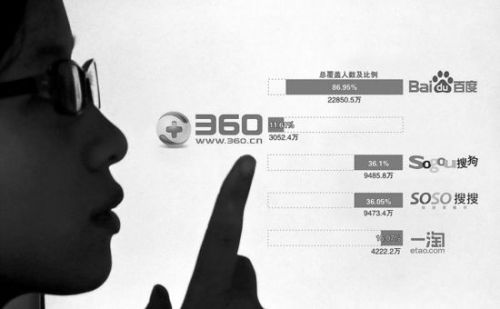
“3B大战”如火如荼(资料图片) 据中国之声《央广新闻》报道,近日,有报道称360违反Robots协议抓取网站信息,并通过浏览器收集隐私数据。这种行为被指不顾行业规则底线,引起业内人士的热议。 有报道说,由于360搜索并不遵守搜索引擎通用的Robots协议,也就是爬虫协议,导致很多网站出于安全和隐私的考虑,不允许搜索引擎抓取的一些内网信息也泄漏在了360搜索上,这些隐私甚至可能包括银行帐号、密码、内部邮件等一些信息。而原本这个爬虫协议是指,网站通过Robots网站告诉引擎哪些页面是可以抓取的,哪些页面是不能抓取的。这个协议也是行业通行的规则,主要依靠搜索引擎来自觉遵守。 部分网友根据这样的线索进行了求证,发现该情况确实存在。有网友表示,公司原本需要动态口令访问的内部网站现在也被360搜索抓取了,这到底是怎么回事?业内人士专家分析,这可能是公司内部有人用360浏览器导致的。 其实从360和百度的这场“3B大战”开始,就有很多百度的合作机构要求内部员工卸载360浏览器,近日一些网友也在微博发出这样的号召,因为隐私问题成为大家比较大的担忧。 以往因为有Robots协议的存在,在百度或者谷歌中进行搜索的时候不会反馈诸如内网信息等敏感信息,所以360这样一个打破行规的举措引发热议。有专家认为,今天360可以一手举着“反垄断”的旗号违反Robots协议,另外也可以一手举着“用户体验”的旗号,通过浏览器来上传用户的隐私。这种局面如果不能得到制止的话,未来互联网企业竞争可能会陷入混乱,用户的网络安全可能也会受到非常大的影响。有业内人士建议,这个问题的彻底解决不仅要依靠法律制度的完善,也需要政府主管部门的有力监管。 相关背景 Robots协议也称作爬虫协议,爬虫规则或者机器人协议等等。网站通过Robots协议告诉搜索引擎哪些网页可以抓取,哪些网页不能抓取。Robots协议是网站国际互联网界通行的一种道德规范,其目的是为了保护网站数据和敏感信息,确保用户个人信息和隐私不被侵犯。因其不是一个命令,所以需要搜索引擎自觉遵守。一些病毒比如malware(马威尔病毒)经常通过忽略Robots协议的方式,获取网站后台数据和个人信息。 国内使用Robots协议最典型的案例是淘宝网和新浪微博拒绝百度搜索,不过绝大多数的中小网站都是要依靠搜索引擎来增加流量,因此通常并不排斥搜索引擎,也很少使用Robots协议。不过Robots协议最深远的影响还是帮助谷歌和百度这样的垄断搜索引擎,遏制后起的竞争者。这是因为谷歌当年在制定这个协议时特意留了一手,其协议中不仅包括是否允许搜索引擎进行搜索的内容,还包括允许谁和不允许谁进行搜索内容。谷歌和百度在实现垄断地位之后,就利用这些排斥性的规则挡住了后来的进入者。微软的必应、国产的搜狗、搜搜等搜索引擎虽然运行了很多年,但搜索的结果始终差强人意,并不是因为它们的技术能力真的不如百度,很大程度上是受到了Robots协议的影响。
责任编辑:边境

|








焦点资讯
-

- 5G时代持续发力6400万像素主摄+90Hz显示屏vivo X30意外曝光
-
驱动中国2019年11月6日消息 前不久,市场调研机构数据表明第三季度国内5G手机市场发货量vivo品牌以54.3%市场占有率名列前茅,iQOO Pro 5G版、vivo NEX3等5G机型在市......
-

- 三星Note 7很惊艳?看完这五点你可能要失望了
-
最近几天,随着三星Note 7发布,网络上一片赞歌,不论是媒体还是消费者对于这款安卓机皇不吝溢美之词。确实,这款手机不论是在做工还是在设计上,都代表了目前安卓手机的最......
-

- 你想要了解的都有!三星Note 7发布前最全汇总
-
目前,三星官方已经放出了Note 7发布会直播页面,看来三星对于这款手机也是相当的重视,在三星手机全球市场份额下滑,尤其是在中国市场中面临着来自国产手机严峻挑战的时候......
-

- 售价惊人!全球首款带夜视相机智能手机诞生,可录4K视频
-
丹麦科技公司Lumigon发布了全球首款带红外夜视相机的智能手机:Lumigon T3。事实上,关注手机行业的消费者应该都知道,这款手机其实是2012年发布的T2继任者。...
-

- FBI通过第三方破解iPhone 苹果还安全吗?
-
关于苹果与FBI之间的矛盾已经持续了好几个月,正当大家都在猜测,双方之间的矛盾还会进一步激化时,事情来了个一百八十度的大转弯!FBI竟然撤诉了,原因是已经破解了枪击案......


